What you’ll need
- A Compute with Hivenet medium instance (4 × RTX 4090 GPUs)
- A valid NVIDIA NGC API key
- You can request one for free from the EVO2-40B page on NVIDIA NIM
Steps
Create the custom NIM template
-
In the Compute console, go to Templates › Create new template.
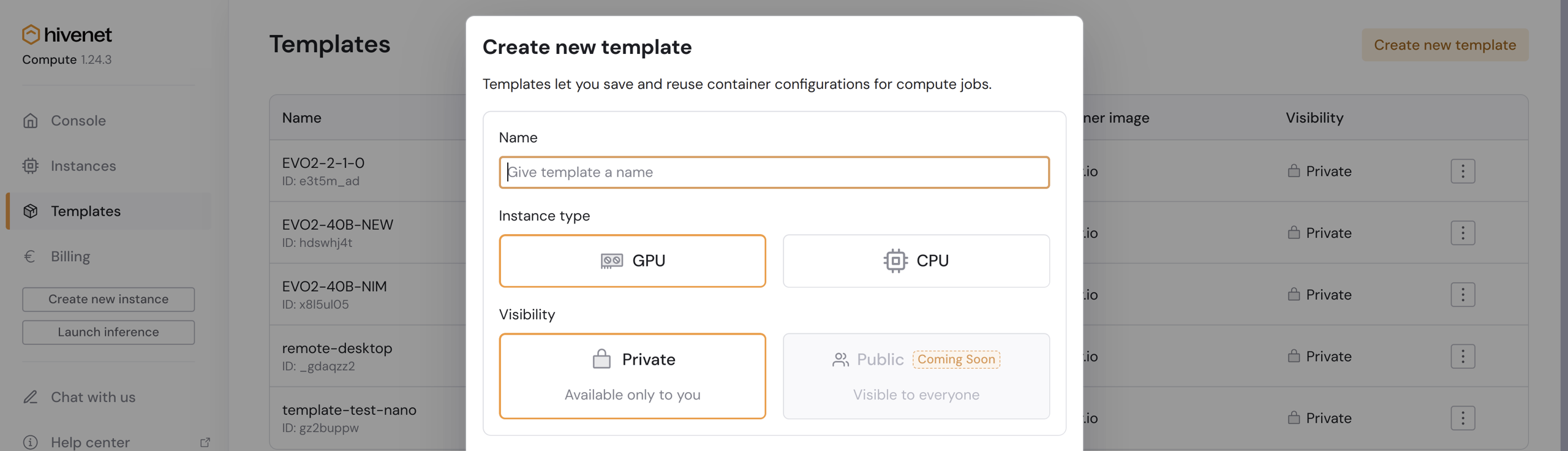
-
Give your template a name, then enter the following custom image URL:
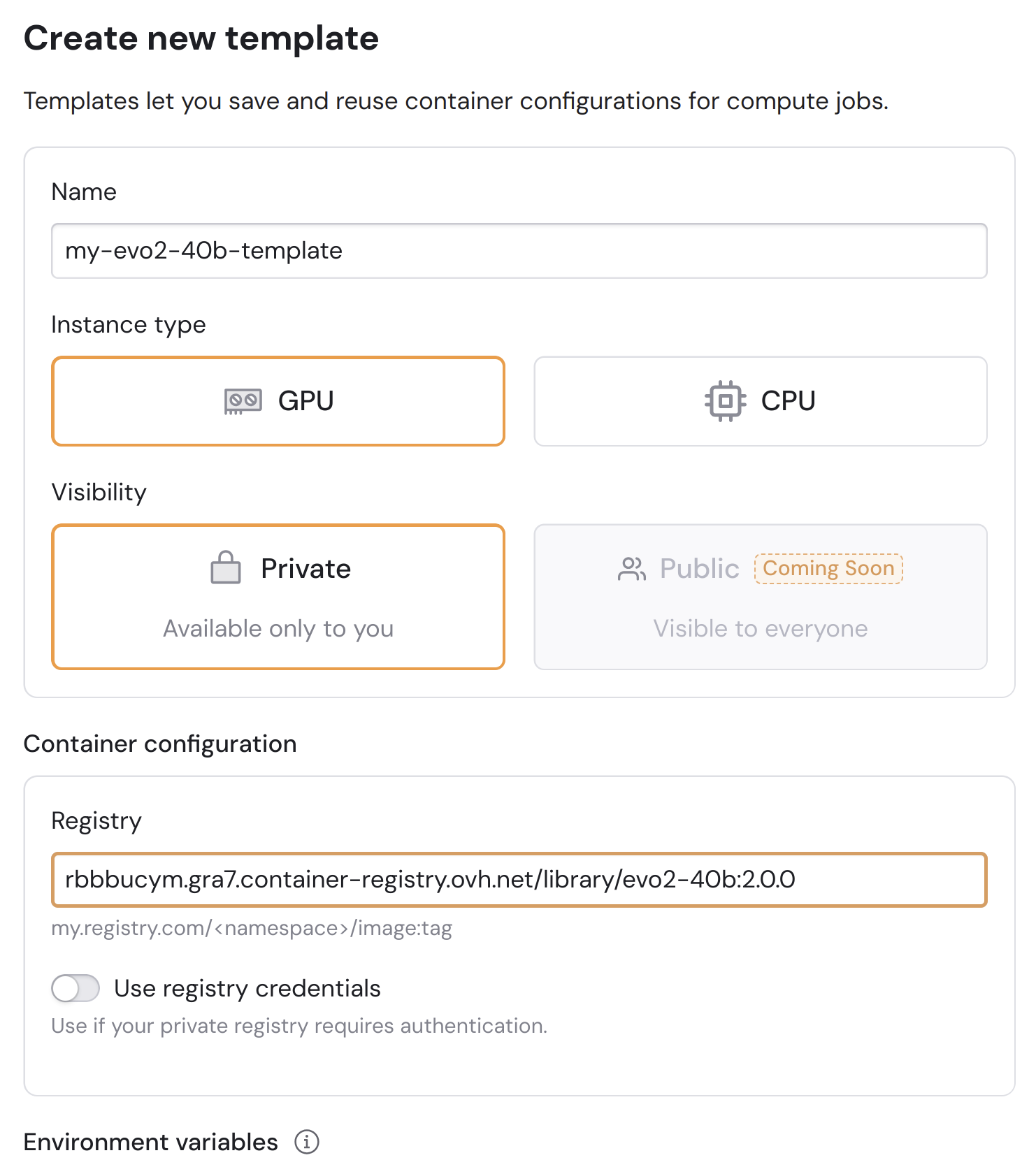
-
Add an environment variable called
NGC_API_KEY, and set your personal NVIDIA API key as the value.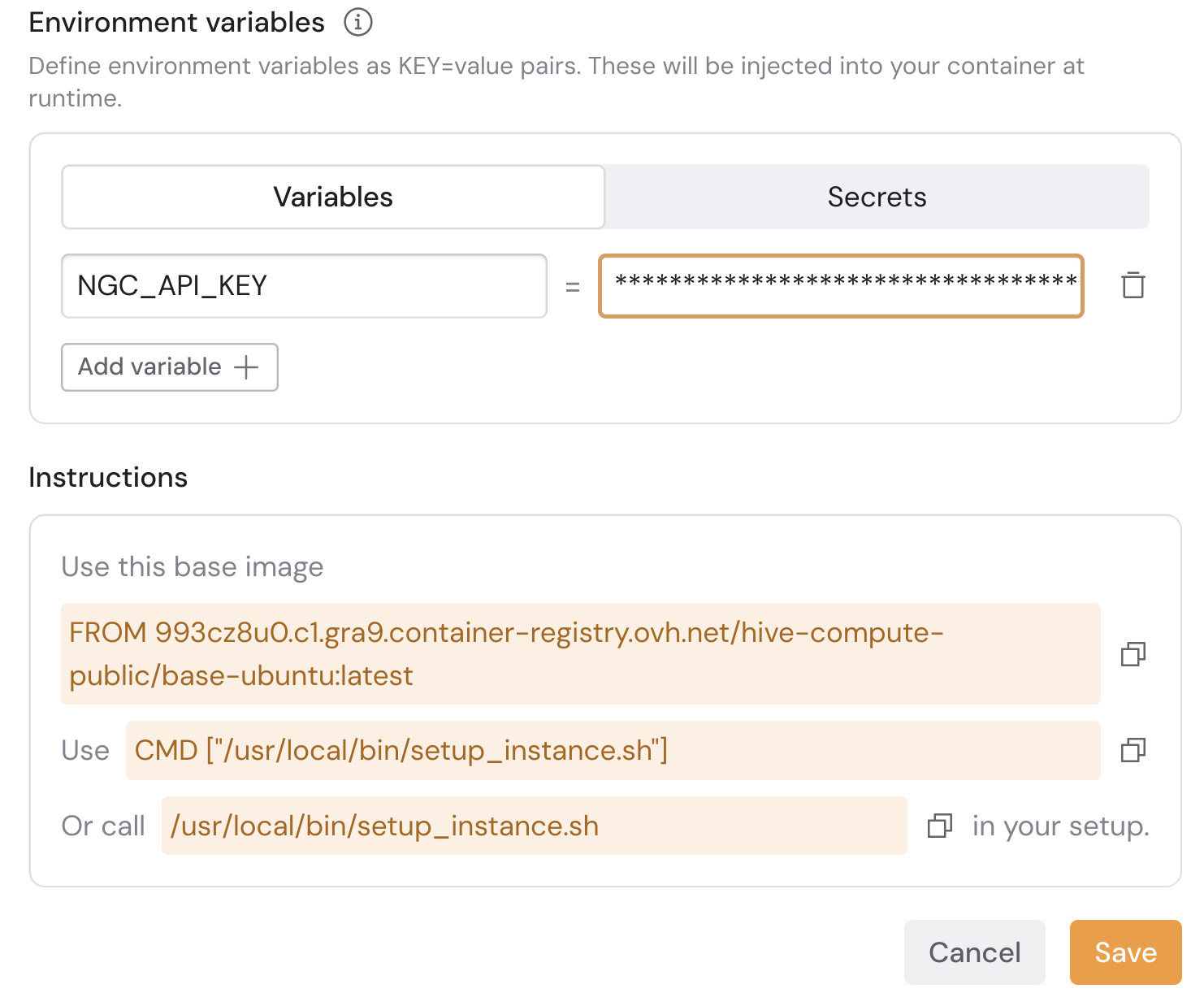
- Click Save.
This container image is based on the official EVO2 40B NIM container and made compatible with Hivenet’s Compute environment.
Create a medium instance
- From the Compute console, select Create new instance.
- Choose your location.
- Under Setup, pick 4 × RTX 4090.
- In Template, select the custom template you just created (e.g.
my-evo2-40b-template). - Under Connectivity, add your public SSH key (if not already added) and expose HTTPS port 8000.
- In Instance name, give your instance a name (e.g.
my-evo2-40b-instance). - Click Create instance and wait until its state changes to Running.
The first start can take several minutes while the image initializes.
Use your EVO2-40B model
Once your instance is running, open the Logs panel.The NIM container automatically downloads the model weights (~ 80 GB).You’ll see messages similar to this once it starts serving:You should receive:You can also check metadata:Expected response (example):Then run:Here is an example output: